Yapay zeka (YZ), endüstrileri dönüştürmeye devam ederken, yapay zeka modellerini yerel(local) olarak çalıştırma ihtiyacı da hızla arttı. Yapay Zeka endüstrileri dönüştürmeye devam ederken, AI modellerini yerelde çalıştırma talebi de hızla artmaktadır. İster yapay zeka modelleri geliştirin ister yapay zekayı kullanıcı olun, yapay zeka modellerini yerel olarak çalıştırmanın birçok avantajı vardır. Gizlilik/güvenlik, düşük gecikme süresi ve çevrimdışı çalışma yeteneği bu avantajlardan sadece birkaç tanesi.
Yerel Yapay Zeka, firmaların yapay zeka geliştirme çalışmalarını değiştiriyor. Verilerin yerinde işlenmesi, geliştiricilerin sürekli bulut kullanımı maliyetine katlanmadan yapay zeka deneyleri ve prototipleme yapmasını sağlıyor. Yerel Yapay Zeka, yenilikler için bir test ortamı haline gelerek değişiklik ve testlerin yapılmasını mümkün kılıyor. Öte yandan, bulut altyapısı ve veri merkezleri daha yoğun iş yüklerini ve büyük ölçekli dağıtımları üstleniyor.
Yapay zeka modellerini yerel olarak çalıştırmak, bazı sektörlere özgü ihtiyaçları karşılamak için de ideal bir çözümdür. Örneğin sağlık sektöründe, hasta verilerinin güvenli bir şekilde analiz edilmesini ve hızlı tanı konulmasını sağlar. Finansal kurumlar, gerçek zamanlı dolandırıcılık tespiti ve risk değerlendirmesi için faydalanır. Üretim sektöründeyse, anında kalite kontrolü ve öngörücü bakım süreçleri için kullanılır.
Bu avantajlardan en iyi şekilde yararlanmak için kullanıcıların donanımlarının, özellikle de GPU’larının, bu tür işlemleri destekleyecek kapasitede olması gerekiyor. Bu noktada, GPU’nun bellek boyutu kritik bir rol oynuyor. Model büyüdükçe daha fazla belleğe ihtiyaç duyulduğu için yerel olarak çalıştırabileceğiniz modellerin boyutunu ve karmaşıklığını doğrudan etkiliyor.
AI Modellerinde Parametre – Precision Dengesi
GPU bellek boyutunu (VRAM) hesaplamak için iki temel kavramı anlamak gerekir; parametreler (parameters) ve hassasiyet (precision).
Parametreler, bir modelin davranışını belirleyen öğrenilmiş değerlerdir. Parametreleri bir yapay zeka modelinin bilgisi gibi düşünebilirsiniz. Bunlar, modelin öğrenme sürecinde yaptığı sayısız küçük ayarlamalardır. Örneğin, bir dil modelinde parametreler, kelimeler ve kavramlar arasındaki ilişkileri anlamasına yardımcı olur. Bir modelin sahip olduğu parametre sayısı arttıkça, daha karmaşık desenleri (patterns) anlayabilir hale gelir, ancak aynı zamanda daha fazla bellek gerektirir.
Hassasiyet (precision), bu parametrelerin bellekte saklanırken ne kadar detaylı tutulduğunu ifade eder. Bunu, sıradan bir cetvel ile son derece hassas bir bilimsel ölçüm cihazı arasındaki fark gibi düşünebilirsiniz. Yüksek hassasiyet (32-bit veya FP32 gibi), bir kumpas ya da mikrometre kullanmak gibidir. Daha doğru ölçümler sağlar, ancak daha fazla yer kaplar çünkü daha çok basamak kaydedilir. Düşük hassasiyet (16-bit veya FP16 gibi) ise basit bir cetvel kullanmak gibidir. Daha az yer kaplar ancak bazı küçük detaylar kaybolabilir.
YZ Modelleri için GPU Belleği (VRAM)
GPU belleği (GPU memory – VRAM) tahmin etmek için ilk adım, modeldeki toplam parametre sayısını bulmaktır. Bunun bir yolu, NVIDIA NGC kataloğunu (NVIDIA NGC catalog) ziyaret etmek ve model adını veya model kartını (model card) incelemektir. Pek çok model, isimlerinde parametre sayısını içerir; örneğin, GPT-3 175B, 175 milyar parametre içerdiğini belirtir. NGC kataloğu ayrıca model mimarisi veya teknik özellikler bölümünde parametre sayıları gibi detaylı bilgiler de sağlar.
Figure 1. NVIDIA NGC Catalog’ta yer alan bir model kart örneği
Bir önceden eğitilmiş modelin (pretrained model) hassasiyetini (precision) belirlemek için, model kartını (model card) inceleyerek kullanılan veri formatı hakkında bilgi edinebilirsiniz. FP32 (32-bit floating-point) genellikle eğitim sırasında veya maksimum doğruluğun (maximum accuracy) kritik olduğu durumlarda tercih edilir. Bu format, en yüksek seviyede sayısal hassasiyet sağlar ancak daha fazla bellek ve hesaplama kaynağı gerektirir.
Öte yandan, FP16 (16-bit floating-point) özellikle Tensor Core’lara sahip NVIDIA RTX GPU’larda performans ve doğruluk (accuracy) arasında iyi bir denge sunar. FP16, FP32’ye kıyasla eğitim ve çıkarım süreçlerinde 2 kata kadar hızlanma sağlar ve yine de iyi bir doğruluk seviyesini korur. Bu nedenle, hangi hassasiyetin kullanılacağını belirlemek, modelin hedef uygulama ihtiyaçlarına bağlıdır.

Figür 2. GPU verimliliğini en üst düzeye çıkarmak için, INT4 (4-bit integer) ve FP8 (8-bit floating-point) gibi daha küçük veri formatları, FP32 (32-bit floating-point) gibi daha büyük formatlara kıyasla bellek kullanımını önemli ölçüde azaltır.
INT8 (8-bit integer) genellikle uç cihazlarda çıkarım işlemleri için veya hız ve verimliliğin öncelikli olduğu durumlarda kullanılır. FP16’ya kıyasla bellek kullanımında 4 kata kadar iyileştirme ve hesaplama performansında 2 kat daha iyi sonuç sunabilir. Bu, kaynakların sınırlı olduğu ortamlarda dağıtım için ideal bir seçenek haline getirir.
FP4 (4-bit floating-point) ise yapay zeka uygulamalarında giderek daha yaygın hale gelen bir hassasiyet formatıdır (precision format). Daha verimli yapay zeka hesaplamalarına doğru önemli bir adımı temsil eder ve bellek gereksinimlerini ve hesaplama yükünü büyük ölçüde azaltırken makul bir doğruluğu (reasonable accuracy) korur.
Bir model kartını (model card) incelerken, “precision” (hassasiyet), “data format” (veri formatı) veya “quantization” gibi terimlere dikkat ederek modelin hangi formatları kullandığını belirleyebilirsiniz. Bazı modeller birden fazla hassasiyet formatını destekleyebilir veya performansı ve doğruluğu optimize etmek için farklı formatları birleştiren karma hassasiyet (mixed precision) yaklaşımlarını kullanabilir.
Gerekli GPU belleğini kabaca tahmin etmek için, parametre sayısını (number of parameters), parametre başına byte sayısı (bytes per parameter) ile çarparak hesaplayabilirsiniz (örneğin, FP32 için 4 byte, FP16 için 2 byte). Daha sonra, optimizer durumları (optimizer states) ve diğer ek yükler (overhead) için bu değeri ikiyle çarpmanız gerekir. Örneğin, FP16 hassasiyetinde 7 milyar parametreli bir model yaklaşık olarak 28 GB GPU belleği gerektirir (7 milyar x 2 byte x 2).
Buradaki hesaplama değişiklik gösterebilir, detaylı bilgi için aşağıdaki linkleri de incelemenizi tavsiye ederiz.
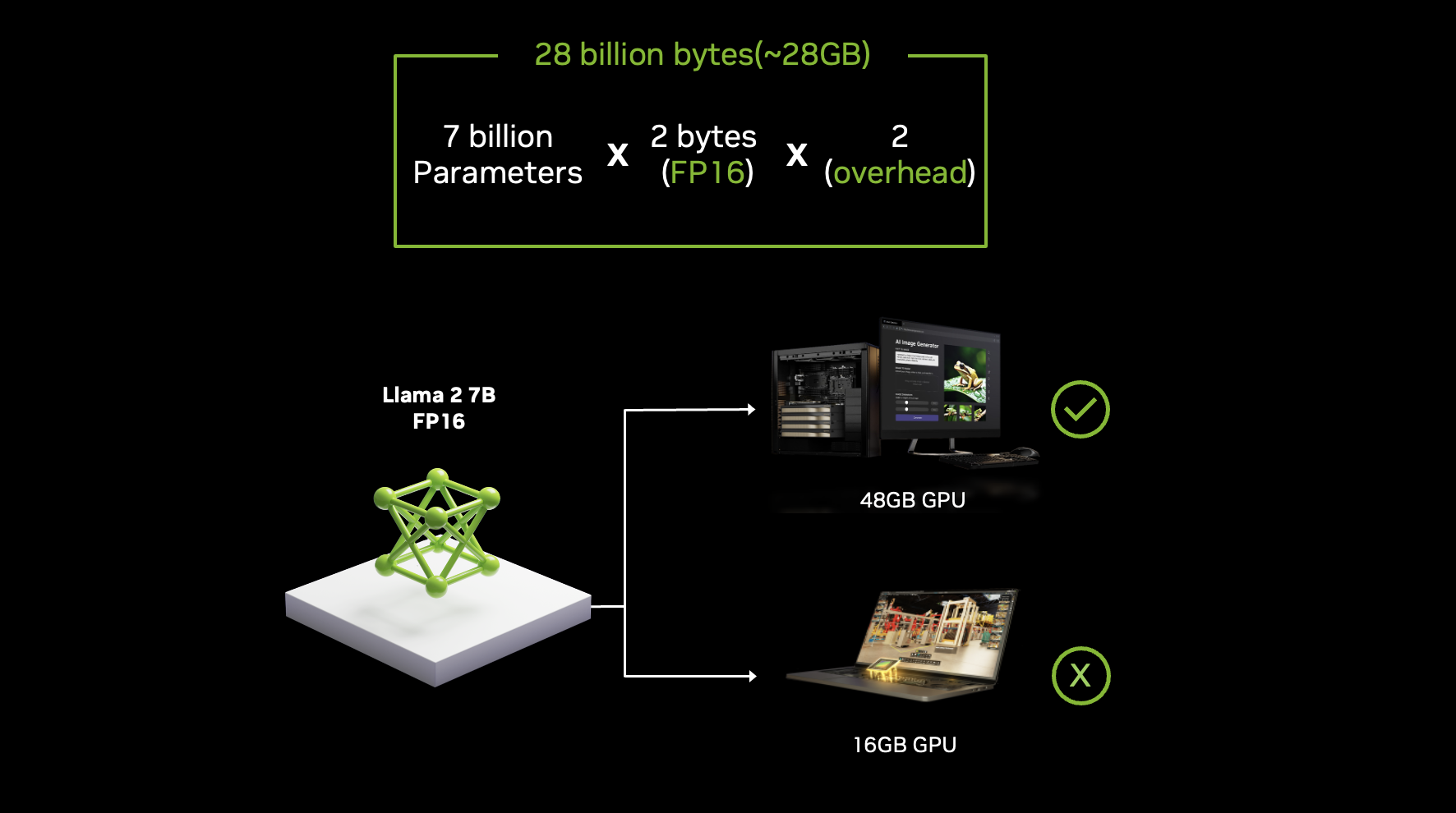
Figür 3. Llama 2 modelini 7 milyar parametre ile FP16 (16-bit floating-point) hassasiyetinde çalıştırmak, en az 28 GB bellek gerektirir. Bu da, gelişmiş yapay zeka iş yükleri için yüksek kapasiteli GPU’ların önemini ortaya koyar.
NVIDIA RTX GPU’lar, yapay zeka modellerini yerel olarak çalıştırmak için gereken yüksek performansı sağlar. NVIDIA RTX 6000 Ada Generation modelinde bulunan 48 GB’a kadar VRAM, büyük ölçekli yapay zeka uygulamaları için bile yeterli bellek sunar. Ayrıca, RTX GPU’lar, yapay zeka hesaplamalarını önemli ölçüde hızlandıran özel Tensor Core’lar içerir ve bu da onları yerel yapay zeka geliştirme (local AI development) ve dağıtımı için ideal hale getirir.
Yapay zeka model boyutunu küçültme: kuantizasyon (Quantization)
Sınırlı bellek kapasitesine sahip GPU’larda daha büyük modeller çalıştırmak isteyen geliştiriciler için kuantizasyon teknikleri (quantization techniques) oyunun kurallarını değiştirebilir. Kuantizasyon, modelin parametrelerinin hassasiyetini düşürerek bellek gereksinimlerini önemli ölçüde azaltır, aynı zamanda modelin doğruluğunu büyük ölçüde korur.
NVIDIA TensorRT-LLM, modelleri 8-bit veya hatta 4-bit hassasiyete sıkıştırabilen (compress) gelişmiş kuantizasyon yöntemleri sunar. Bu sayede, daha az GPU belleği ile daha büyük modeller çalıştırılabilir. Bu tür teknikler, hem bellek kullanımını optimize etmek hem de yerel yapay zeka uygulamalarını genişletmek için kritik bir rol oynar.
Büyük ölçekli yapay zeka projeleriniz için OpenZeka İş İstasyonu çözümleri
NVIDIA RTX 6000 Ada mimarisi ile güçlendirilmiş, yüksek performanslı işlemcilere ve geniş depolama kapasitesine sahip 4× RTX 6000 Ada içeren özel YZ iş istasyonumuzu keşfedin. LLM ve Generative AI uygulamalarınız için optimize edilen bu iş istasyonları, karmaşık modellerin eğitiminde ve çıkarım süreçlerinde maksimum hız ve doğruluk sağlar.
Buradaki linke tıklayarak çözüm hakkında daha detaylı bilgi alabilir ve benchmark sonuçlarını inceleyebilirsiniz.
OPENZEKA HABERLERİ



OPENZEKA HABERLERİ
Hesaplarınızda paylaşmak ister misiniz?