
Megatron 530B gibi karmaşık modeller, yapay zekanın daha büyük sorunları çözebilmesini sağlıyor. Fakat bunun yanında, modellerin karmaşıklığı arttıkça da AI hesaplama platformları için yeni zorluklar oluşuyor:
- Bu modeller, makul bir sürede eğitilmeliler.
- Çıkarım işlemini gerçek zamanlı olarak yapabilmeliler.
Eğitim ve çıkarım için çeşitli modellerde gerekli performansı sağlayabilen çok yönlü bir AI platformu bu zorlukların üstesinden gelebilir.
MLPerf, veri merkezleri ve uç platformlarının sağladığı performansı değerlendirmek için yarım düzine uygulamada, çıkarım sonucunu, gecikme süresini ve enerji verimliliğini ölçen endüstri standardı AI karşılaştırmasıdır.
NVIDIA, MLPerf Inference 2.0’da hem veri merkezi GPU’ları hem de geçtiğimiz günlerde dağıtımına başlanan NVIDIA Jetson AGX Orin SoC platformu ile sınırları belirleyen sonuçlar verdi.
Bu platformları maksimum verimde kullanmak için sadece donanım değil, güçlü bir yazılım ve optimizasyon çalışması da gerekiyor.
Sonuçlar
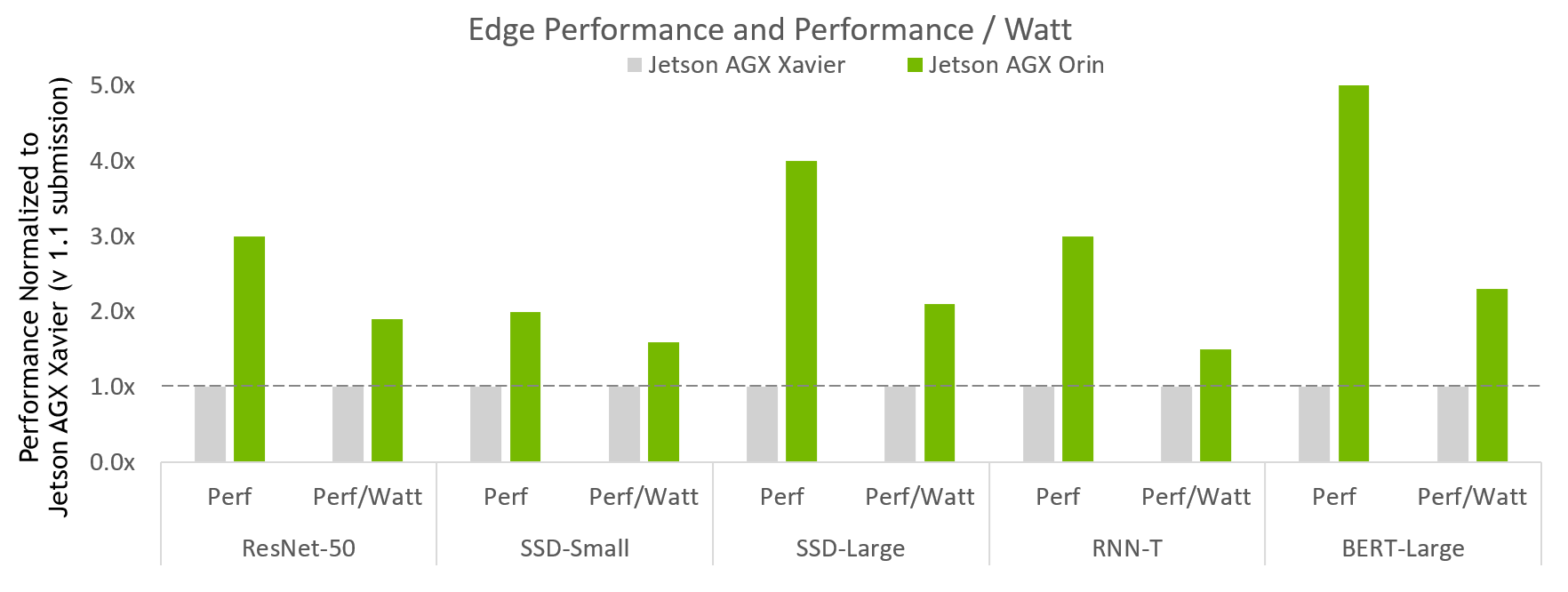
Şekil 1. NVIDIA Jetson AGX Orin Performans Artışı
MLPerferf Performans/Watt sonuçları. NVIDIA Xavier AGX Xavier: 1.1-110 ve 1.1-111 | Jetson AGX Orin: 2.0-140 ve 2.0-141. Kaynak: http://www.mlcommons.org/en.
Şekil 1, Jetson AGX Orin’in önceki nesle göre 5 kata kadar daha fazla performans sağladığını gösteriyor. Yapılan bütün testlerin ortamala sonucuna göre de 3.4 kat daha fazla performans sağlıyor. Performans artışı dışında AGX Orin, 2.3 kat daha fazla enerji tasarruflu.
Jetson Orin AGX, birden fazla eşzamanlı AI çıkarım veri hattı için 275 TOPS’a kadar AI hesaplaması ve ayrıca birden fazla sensör için yüksek hızlı arayüz desteği sunan bir SoC’dir (System on Chip). NVIDIA Jetson AGX Orin Geliştirici Kit sağladığı yüksek performans ve enerji tasarrufuyla, üretim, lojistik, perakende, hizmet, tarım, akıllı şehir, sağlık ve yaşam bilimleri için gelişmiş robotik ve uç AI uygulamaları oluşturmanızı sağlıyor.
NVIDIA, veri Merkezi kategorisinde, tüm kullanım senaryolarında AI çıkarım performansı liderliğini devam ettiriyor.
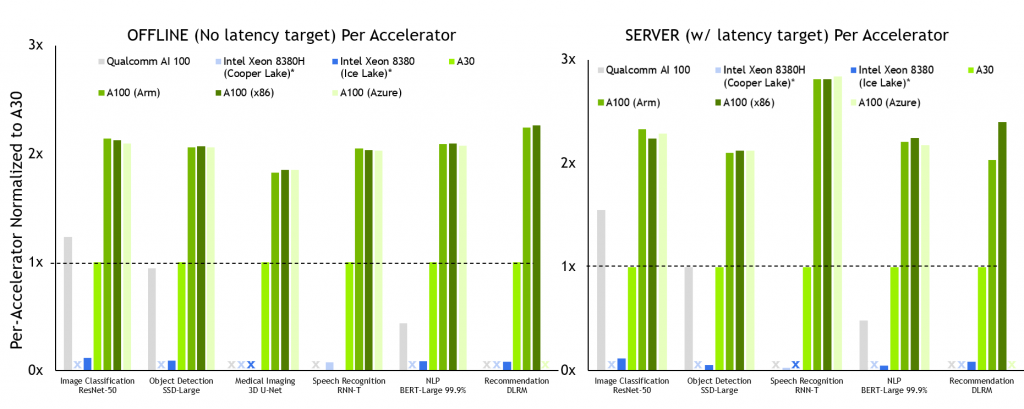
Şekil 2. NVIDIA A100 hızlandırıcı başına performans
MLPerf v2.0 Çıkarımı Kapatıldı; Veri Merkezi Çevrimdışı ve Sunucuda raporlanan hızlandırıcı sayısı kullanılarak ilgili gönderimler için en iyi MLPerf sonuçlarından elde edilen hızlandırıcı başına performans. Qualcomm AI 100: 2.0-130, MLPerf v.1.1 gönderiminden Intel Xeon 8380: 1.1-023 ve 1.1-024, Intel Xeon 8380H 1.1-026, NVIDIA A30: 2.0-090, NVIDIA A100 (Arm): 2.0-077, NVIDIA A100 (x86): 2.0-094. Kaynak: http://www.mlcommons.org/en.
NVIDIA A100, görüldüğü gibi hem çevrimdışı hem de sunucu senaryolarındaki tüm testlerde hızlandırıcı başına en iyi performansı sağlıyor.
A100’ü aşağıdaki konfigürasyonlarda test edildi:
- x86 (AMD Epyc 7742) CPU’larla eşleştirilmiş A100 SXM
- x86 (AMD Epyc 7742) CPU’larla eşleştirilmiş A100 PCIe
- Arm CPU (NVIDIA Ampere Architecture Altra Q80-30) ile eşleştirilmiş A100 SXM
Tüm konfigürasyonlar, Arm yazılım yığınının hazır olduğunu ve A100’ün şirket içi ve bulutta yaklaşık olarak aynı çıkarım performansı sağladığını kanıtlıyor.
A100, yalnızca CPU kullanım testinde (RNN-T, Sunucu senaryosu) 105 kata kadar daha fazla performans sunar. A30’a, A100 gibi bütün veri merkezi kategorisi testleri yapıldı ve biri hariç tüm iş yüklerinde liderlik düzeyinde performans sağladı.
Optimizasyonlar
Yüksek çıkarım performansı elde etmek için, güçlü donanımların optimize edilmiş ve çok yönlü yazılımla beraber kullanıldığı tam bir yığın yaklaşımına ihtiyaç duyulur. NVIDIA TensorRT ve NVIDIA Triton Çıkarım Sunucusu, çeşitli kullanım durumları arasında çok yüksek çıkarım performansı sağlamada önemli roller oynar.
Jetson AGX Orin Optimizasyonu
NVIDIA Orin’in yeni NVIDIA Ampere Mimarili iGPU’su (integrated GPU), NVIDIA TensorRT 8.4 tarafından desteklenmektedir. TensorRT, yüksek MLPerf performansı için SoC’nin en önemli bileşenidir. Optimize edilmiş GPU çekirdeklerinden oluşan kapsamlı TensorRT kütüphanesi, yeni mimariyi desteklemek için genişletildi. TensorRT Builder bu çekirdekleri otomatik olarak alır.
Ayrıca, MLPerf ağlarında kullanılan, res2 (resnet50) ve qkv to context (BERT) dahil eklentilerin tümü, NVIDIA Orin’e taşındı ve TensorRT 8.4’e eklendi. Ayrık GPU hızlandırıcılara sahip sistemlerin aksine, SoC DRAM CPU ve iGPU tarafından paylaşıldığından girişler(input) ana bilgisayar belleğinden cihaz belleğine kopyalanmaz.
NVIDIA, iGPU’ya ek olarak, çevrimdışı senaryoda CV ağlarında (resnet50, ssd-mobilenet, ssd-resnet34) maksimum sistem performansı için iki tane derin öğrenme hızlandırıcısı (DLA) kullanıyor.
NVIDIA Orin, yeni nesil DLA HW’ye sahip. DLA derleyicisi, bu donanım geliştirmelerinden en yüksek seviyede faydalanabilmek için, herhangi bir uygulama kaynak kodunu değiştirmeden, TensorRT sürüm yükseltmelerinde otomatik olarak kullanılabilen aşağıdaki NVIDIA Orin özelliklerini ekledi:
- SRAM chaining: DRAM’den okuma/yazma işlemlerini önlemek için ara tensörleri yerel SRAM’de tutar, bu da gecikmeyi ve platform DRAM kullanımını azaltır, ayrıca GPU çıkarımı ile girişimi azaltır.
- Evrişim + pooling füzyonu: INT8 evrişim + bias + ölçek + ReLU, sonraki bir pooling düğümü ile birleştirilebilir.
- Evrişim + eleman bazında füzyon: INT8 evrişim + eleman bazında toplam, sonraki bir ReLU düğümü ile birleştirilebilir.
İki DLA hızlandırıcısının batch boyutu, GPU+DLA toplam performansının doğru dengesini elde etmek için hassas bir şekilde ayarlandı. Ayarlama, DLA motorunun GPU yedek çekirdekleri için zamanlama çakışmalarını en aza indirme ihtiyacını dengelerken, SoC’nin paylaşılan DRAM bant genişliğinden kaynaklanan genel potansiyel açlığını da azaltır.
3D-UNet tıbbi görüntüleme
3D-UNet tıbbi görüntüleme iş yükü KITS19 veri seti ile geliştirildi. Yeni oluşturulan böbrek tümörü görüntüleri veri seti, değişen boyutlarda çok daha büyük görüntülere sahiptir ve görüntü başına çok daha fazla işleme ihtiyaç duyar.
KiTS19 veri seti, yüksek performanslı, enerji verimli çıkarım elde etmede yeni zorlukları beraberinde getiriyor:
- KiTS19’da kullanılan giriş tensörlerinin şekli 128x192x320 ile 320x448x448 arasında değişmektedir; en büyük giriş tensörü, en küçük giriş tensöründen 8,17 kat daha büyüktür.
- Çıkarım sırasında 2 GB’den büyük tensörlere ihtiyaç duyuyor.
- ROI şeklinde (128x128x128), büyük bir örtüşme faktörü (%50) ile kayan bir pencere vardır.
Bu zorlukları çözebilmek ve görüntüleri işleyebilmek için yeni bir kayan pencere yöntemi geliştirildi:
- Her bir giriş tensörünü örtüşme faktörüne bağlı kalarak ROI şeklinde dilimleyin.
- Belirli bir giriş tensörü için tüm kayan pencere dilimlerini işlemek için bir döngü kullanın.
- Her kayan pencerenin çıkarım sonucunu ağırlıklandırın ve normalize edin.
- Kayan pencere çıkarımlarının toplu sonuçlarının ArgMax’ına göre son segmentasyon çıktısını alın.
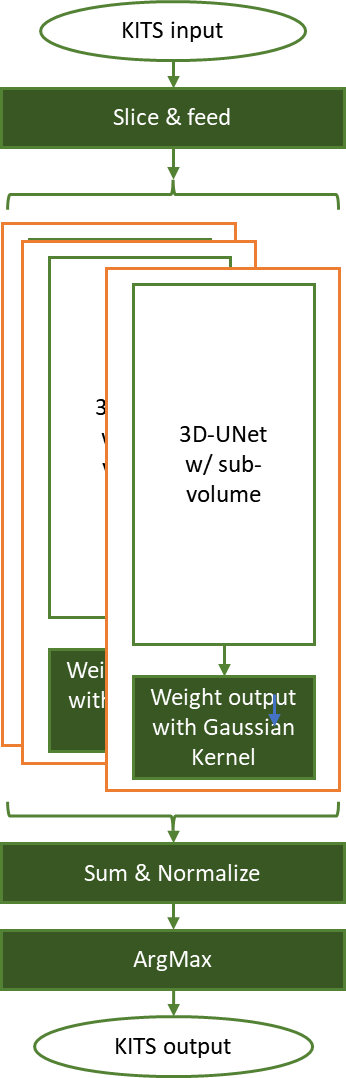
Şekil 3, 3D-UNet, kayan pencere yaklaşımı kullanarak KiTS19 böbrek tümörü segmentasyon çıkarım görevini gösteriyor
Şekil 3’te, her bir giriş tensörü örtüşme faktörü (%50) ile ROI şeklinde (128x128x128) dilimlenir ve önceden eğitilmiş ağa beslenir. Her kayan pencere çıktısı daha sonra normalleştirilmiş sigma = 0.125 Gauss çekirdeği ile özellikleri yakalamak için en uygun şekilde ağırlıklandırılır.
Çıkarım sonuçları, orijinal girdi tensör şekline göre toplanır ve bu ağırlıklandırma faktörleri için normalize edilir. ArgMax işlemi daha sonra segmentasyon bilgisini keserek arka planı, normal böbrek hücrelerini ve tümörleri işaretler.
Bu uygulama, segmentasyonu temel gerçekle (ground truth) karşılaştırır ve kıyaslama doğruluğunu belirlemek için bir DICE puanı hesaplar. Sonucu şekil 4’te gösterilmiştir.
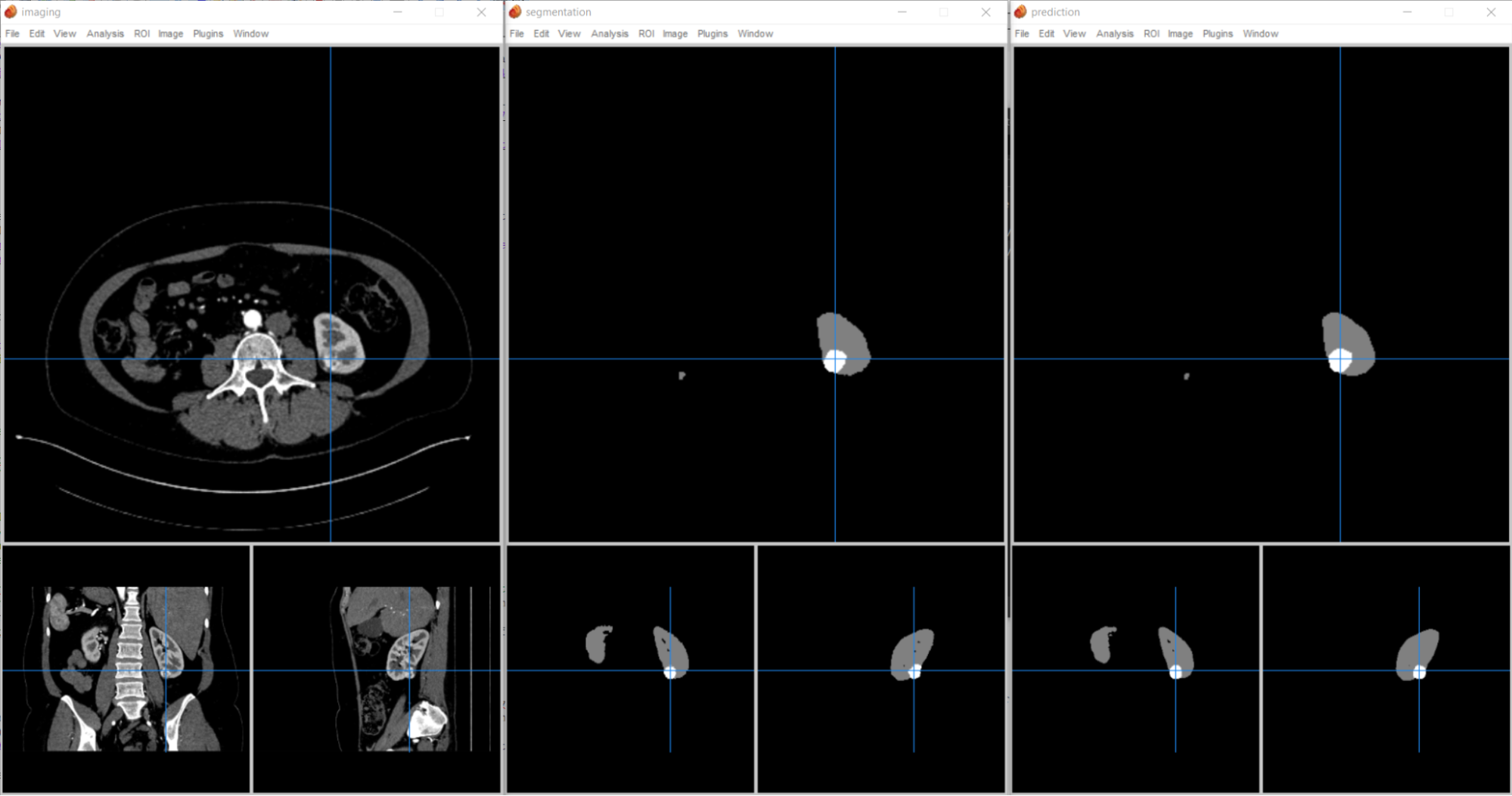
Şekil 4. (solda) Çıkarım görevinde bir girdi olan 3D CT görüntüsü. (ortada) Normal böbrek hücreleri (gri) ve tümörleri (beyaz vurgulanmış) gösteren kesin bilgi segmentasyonu sonucu. (sağda) 3D-UNet KiTS19’dan çıkarım sonucu.
NVIDIA, 5 yıldan fazla bir süredir veri merkezi GPU’larında INT8 hassasiyetini (precision) desteklemektedir. Bu hassasiyet, FP16 ve FP32 hassasiyet seviyelerine kıyasla doğrulukta sıfıra yakın kayıpla birçok modelde önemli hızlanmalar sağlıyor.
3D-UNet için, kalibrasyon setinden görüntüleri TensorRT IInt8MinMaxCalibrator kullanarak kalibre ederek INT8 kullanıldı. Bu uygulama, FP32 referans modelinde %100 doğruluk sağlıyor, böylece kıyaslamanın hem yüksek hem de düşük doğruluk modlarını yapılabilir kılıyor.
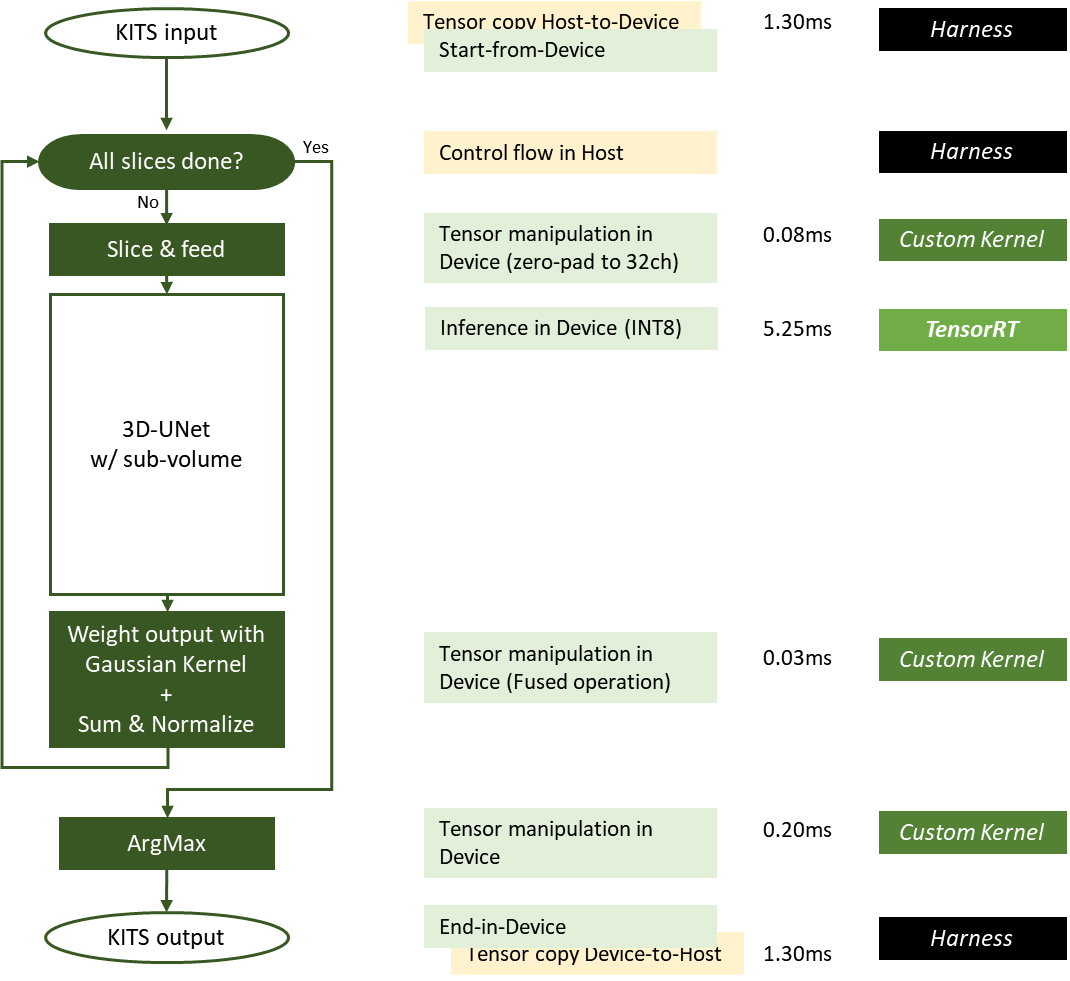
Şekil 5 MLPerf-Inference v2.0 testinde kullanılan NVIDIA 3D-UNet KiTS19 uygulaması
Şekil 5’te yeşil kutular cihaz GPU’sunda, sarı kutular host CPU’sunda yürütülmektedir. Kayan pencere çıkarımı için gereken bazı işlemler, füzyon işlemler olarak optimize edilmiştir.
GPUDirect RDMA ve depolama, ana bilgisayardan cihaza veya cihazdan ana bilgisayara veri hareketinin kullanılması en aza indirilebilir veya ortadan kaldırılabilir. Her çalışmanın gecikme süresi, boyutu, ortalama girdi boyutuna yakın olan bir girdi örneği için DGX-A100 sisteminden ölçülür. Dilimleme çekirdeği ve ArgMax çekirdeği için gecikme, giriş görüntüsünün boyutuyla orantılı olarak değişir.
Uygulanan bazı optimizasyonlar:
- Ağırlıklandırma için kullanılan Gauss çekirdek yamaları artık önceden hesaplanıyor, diskte saklanıyor ve kıyaslamanın zamanlanmış kısmı başlamadan önce GPU belleğine yükleniyor.
- Ağırlıklandırma ve normalizasyon, 3D giriş tensöründe %50 örtüşme kayan pencere için gerekli 27 önceden hesaplanmış yama kullanılarak füzyon bir işlem olarak optimize edilmiştir.
- Dilimleme, ağırlıklandırma ve ArgMax işlemlerini gerçekleştiren özelleştirilmiş CUDA çekirdekleri, tüm bu işlemlerin GPU’da gerçekleşmesi için kodlanır ve H2D/D2H veri aktarımı ihtiyacını ortadan kaldırır.
- INT8 LINEAR bellek düzenindeki giriş tensörü, KiTS19 giriş seti tek kanal olduğundan H2D aktarımında minimum miktarda veri sağlar.
- TensorRT, NC/32DHW32 formatında INT8 girişi gerektirir. GPU global belleğindeki bitişik bir bellek bölgesinde, sıfır noktasına dilimleme gerçekleştiren ve INT8 LINEAR giriş tensör dilimini INT8 NC/32DHW32 biçiminde yeniden biçimlendiren özelleştirilmiş bir CUDA çekirdeği kullanıldı.
GPU içindeki tensöre zero-padding uygulamak ve yeniden biçimlendirmek, 32 kat daha fazla veri içeren H2D aktarımından çok daha hızlıdır. Bu optimizasyon, genel performansı önemli ölçüde artırırken, sistem kaynağını da serbest bırakmış olur.
TensorRT motoru, kayan pencere dilimlerinin her birinde çıkarım yapmak için oluşturulmuştur. 3D-UNet dense model olduğu için, batch boyutunun artmasının motorun çalışma süresini de orantılı olarak artırdığını bulundu.
NVIDIA Triton Optimizasyonları
NVIDIA, Triton Inference Server’ın çok yönlülüğünü göstermeye devam ediyor. Triton Inference Server, NVIDIA Triton’un AWS Inferentia üzerinde çalıştırılmasını da destekler. NVIDIA Triton, Inferentia için optimize edilmiş PyTorch ve TensorFlow modellerini çalıştırmak için Python backend’i kullanır.
NVIDIA Triton ve torch-nöron kullanan NVIDIA testleri, Inferentia’da yerel çıkarım performansının %85 ila %100’ünü elde etti.
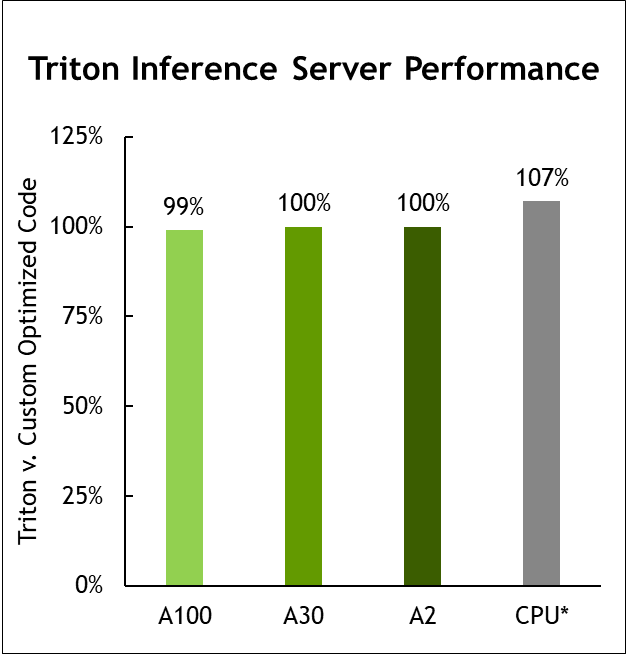
Şekil 6 Triton Inference Server performansı
Veri Merkezinde çevrimdışı raporlanan hızlandırıcı sayısı kullanılarak ilgili testler için en iyi MLPerf sonuçlarından elde edilen hızlandırıcı başına performans. Gönderilen bütün testlerin geometrik ortalaması. Aynı CPU, 1.0-16, 1.0-17, 1.0-19 gönderileri ile konfigürasyonları karşılaştırmak için MLPerf Inference 1.1’den alınan Intel gönderi verilerine dayalı CPU karşılaştırması. CPU üzerinde NVIDIA Triton: 2.0-100 ve 2.0-101. A2: 2.0-060 ve 2.0-061. A30: 2.0-091 ve 2.0-092. A100: 2.0-094 ve 2.0-096. Kaynak: http://www.mlcommons.org/en
NVIDIA Triton artık AWS Inferentia çıkarım işlemcisini destekliyor ve yalnızca AWS Neuron SDK üzerinde çalışmaya neredeyse eşit performans sunuyor.
Daha fazla bilgi için Çıkarım için Teknik Genel Bakış.
Yazının kaynağına buradan ulaşabilirsiniz.
OPENZEKA HABERLERİ




OPENZEKA HABERLERİ
Hesaplarınızda paylaşmak ister misiniz?



