
Görsel dil modelleri (VLM’ler), hem görsel hem de metinsel verileri anlayabilen ve işleyebilen yapay zeka modelleridir. Bu modeller, görsel soru yanıtlama, görüntü başlığı oluşturma, resimlere açıklama ekleme, metinden görsel oluşturma gibi geniş bir görev yelpazesini başarıyla yerine getirebilir.
Doğal dil işleme (NLP) ve bilgisayarlı görü (CV) teknolojilerinin son yıllardaki hızlı gelişimi, yapay zeka modellerinin yalnızca metinsel içerikleri değil, aynı zamanda görsel verileri de anlamasını ve yorumlamasını mümkün hale getirdi. Bu iki alanın birleşimi, hem görsel hem de metinsel verileri işleyip anlayabilen görsel dil modellerinin (VLM) geliştirilmesine zemin hazırladı. Bu tür görevler, daha önce ayrı ve özelleşmiş sistemler gerektirirken, VLM’ler bu süreçleri tek bir birleşik çözümle sunar.
VLM’lerin Çalışma Mantığı ve Teknolojileri
Doğal dil işleme (NLP), bilgisayarlara insan dilini yorumlama, işleme ve anlama yeteneği veren bir makine öğrenimi teknolojisidir.
Bilgisayarlı görü (CV) ise makinelerin nesneleri ve diğer görsel öğeleri tanıyarak, görüntü ve video gibi görsel verileri yorumlamasını ve analiz etmesini sağlayan bir teknolojidir.
Bu her iki alanı uyarlayarak metin ve görüntü üzerinde görevleri yerine getirebilen VLM’ler transformatör tabanlı mimarileri kullanır. Transformatör tabanlı mimariler( detaylı bilgi için bakınız: (https://blog.openzeka.com/ai/transformer-modeli-nedir/) çok modlu girdileri işleyecek şekilde kurgulanmıştır ve bu sayede VLM’lerin görsel ve metinsel veriler arasındaki karmaşık ilişkileri yakalaması sağlanmıştır.
Tipik bir VLM mimarisi iki ana bileşenden oluşur: görüntü kodlayıcı ve metin çözücü.
- Görüntü Kodlayıcı (Image Encoder): Görsel verileri işleyerek nesne, renk, doku gibi özellikleri çıkarır ve bu veriyi modelin anlayabileceği bir formata dönüştürür.
- Metin Çözücü (Text Decoder): Metinsel verileri işleyerek kodlanmış görsel özelliklere dayalı bir çıktı üretir.
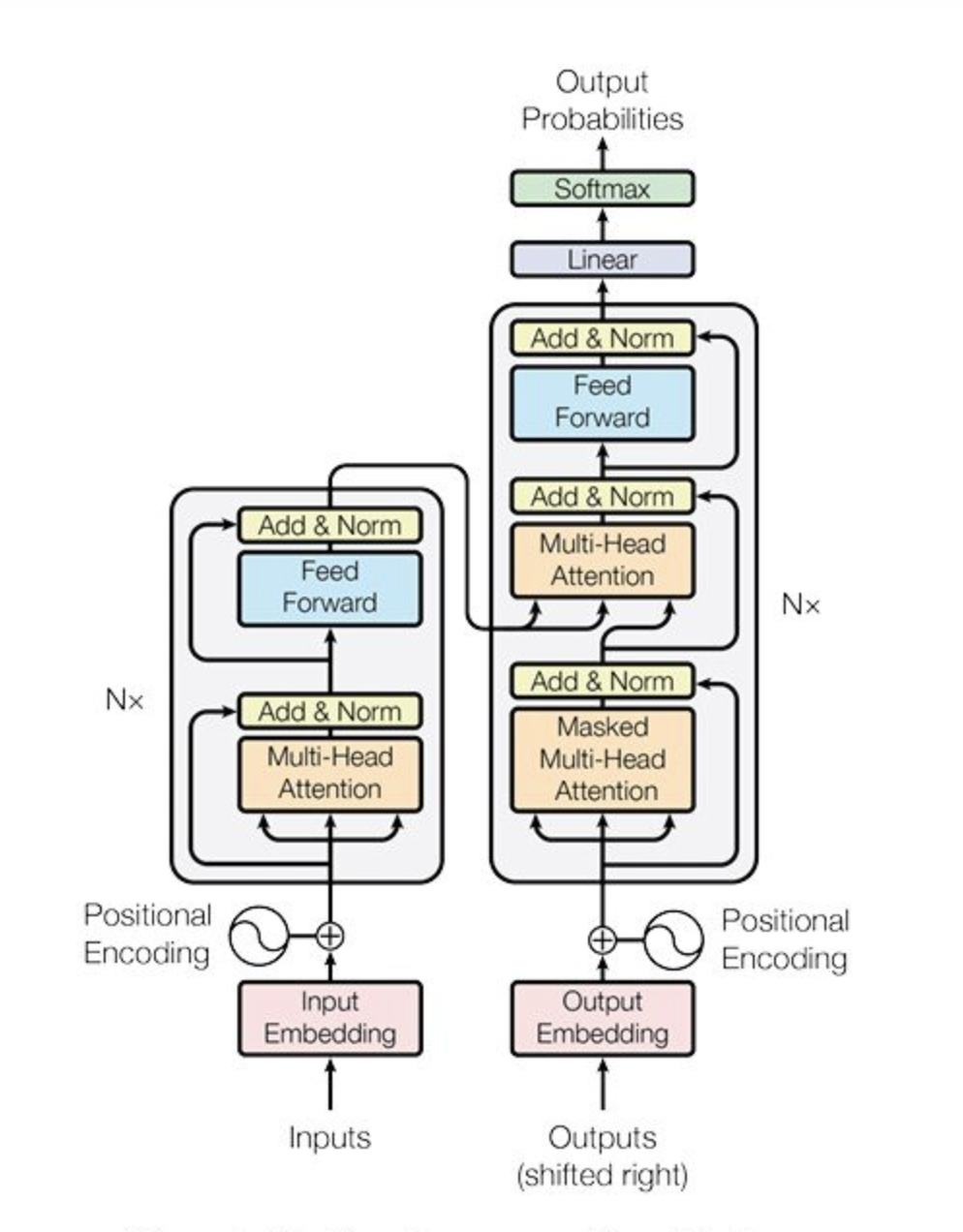
Bu iki bileşeni bir araya getirdiğimizde, VLM’ler görselleri ayrıntılı bir şekilde tanımlamak, gördükleri hakkında soruları yanıtlamak ve hatta metin açıklamalarına dayalı olarak yeni görüntüler oluşturmak gibi yeteneklere sahip oluyorlar.
Örneğin, bir VLM modeli, bir manzara fotoğrafını analiz ederek “Gün batımında dağların üzerinde süzülen bir kuş sürüsü” şeklinde bir başlık oluşturabilir ya da bir metne dayanarak “yağmurlu bir akşam vakti” içeren yeni bir görsel üretebilir.
VLM’lerin bu süreçte izlediği adımlar şu şekilde sıralanabilir:
1. Görsel Analiz
Görsel kodlayıcı (image encoder), verilen görüntüyü analiz ederek temel görsel özelliklerini temsil eden bir kod oluşturur. Bu kod, görüntünün temeli olarak düşünülebilir.
2. Bilgiyi Birleştirme
Metin kod çözücü (text decoder), bu görsel kodu alır, varsa metin girdisiyle (prompt) (örneğin bir soru) birleştirir ve bu bilgiyi birlikte işler. Bu sayede model, hem görsel hem de metinsel bilgileri bütüncül bir şekilde değerlendirebilir.
3.Çıktı Üretimi
Metin kod çözücü, elde edilen birleşik anlayışı kullanarak bir yanıt üretir. Bu yanıt, bir görüntüyü açıklayan bir başlık (caption) olabileceği gibi, sorulan bir soruya verilen bir cevap da olabilir.
VLM’lerin çoğu, görüntü kodlayıcısı olarak Vision Transformer (ViT) kullanır. ViT, büyük ölçekli görüntü veri setlerinde önceden eğitilmiş olup, multimodal görevlerde ihtiyaç duyulan görsel özellikleri etkili bir şekilde yakalayabilir.
VLM Geliştirmede Karşılaşılan Zorluklar
VLM geliştirme sürecinde en büyük zorluklardan biri, hem görsel hem de metinsel bilgiyi temsil eden büyük ve çeşitlilik içeren veri setlerine olan gereksinimdir. Bu tür veri setleri, modellerin multimodal içeriği doğru bir şekilde anlaması ve üretmesi için hayati önem taşır.
VLM’leri eğitmek için, modele görüntüler ve bunların karşılık gelen metinsel açıklamaları çiftler halinde sunulur. Bu süreç, modelin görsel unsurlar ile dilsel ifadeler arasındaki karmaşık ilişkileri öğrenmesini sağlar.
Hesaplama Gereksinimleri
VLM’lerin eğitimi ve kullanıma sunulması, oldukça yüksek düzeyde hesaplama gücü gerektirir. Bu durum, güçlü donanım altyapısına sahip olmayan organizasyonlar için ciddi bir engel teşkil edebilir.
Bu zorlukların üstesinden gelmek için aşağıdaki maddeler dikkate alınmalıdır:
Model sıkıştırma teknikleri kullanmak: Model boyutunu küçülterek daha az kaynakla çalışmasını sağlamak.
Model mimarisini optimize etmek: Modelin yapısını daha verimli hale getirerek performansı artırmak.
Donanım hızlandırıcılarından faydalanmak: Profesyonel GPU’lar gibi yüksek performanslı donanımları kullanarak işlem sürelerini kısaltmak.
Bu çözümler, VLM’lerin daha erişilebilir hale gelmesine yardımcı olurken, firmaların bu ileri teknolojileri daha geniş ölçekte benimsemelerine olanak tanır.
OpenZeka olarak, bahsi geçen yüksek hesaplama kabiliyetine sahip donanımları kullanıcılara sağlamaktayız. Profesyonel seviye LLM workstation ürünlerinden, DGX Podlara kadar farklı performansa sahip ürünleri web sitemizden inceleyebilirsiniz. Ayrıca ürün seçimi konusunda desteğe ihtiyaç duyarsanız bizlere ulaşmanız yeterli. Aşağıdaki formu doldurup, uzman ekibimizle iletişime geçebilirsiniz.
OPENZEKA HABERLERİ




OPENZEKA HABERLERİ
Hesaplarınızda paylaşmak ister misiniz?



