
Sentetik veriler, bilgisayar simülasyonlarının veya algoritmalarının gerçek dünya verilerine alternatif olarak oluşturduğu açıklamalı bilgilerdir. Başka bir deyişle, sentetik veriler gerçek dünyadan toplanmak veya gerçek dünyada ölçülmek yerine dijital dünyalarda oluşturulur.
Sentetik veriler yapay olsa da matematiksel veya istatistiksel olarak gerçek dünya verilerini yansıtır. Araştırmalar, bir yapay zeka modelini eğitmek için yapay veri kullanmanın, gerçek nesnelere, olaylara veya insanlara dayalı verilerden daha iyi olabileceğini gösteriyor. Bu nedenle derin sinir ağı geliştiricileri, modellerini eğitmek için giderek artan bir şekilde sentetik veri kullanıyor.

Rusya, St. Petersburg’daki Steklov Matematik Enstitüsü’nden Sergey I. Nikolenko’nun 156 sayfalık raporu, sentetik verilerle ilgili 719 makaleye atıfta bulunuyor. Nikolenko, derin öğrenmenin daha da geliştirilmesi için sentetik verilerin gerekli olduğunu ve daha keşfedilmeyi bekleyen birçok potansiyel kullanım durumunun bulunduğu sonucuna varıyor.
Sentetik verinin yükselişi, yapay zeka öncüsü Andrew Ng’in makine öğrenimine yönelik daha veri merkezli bir yaklaşıma geniş bir geçiş çağrısı yapmasıyla geliyor. Pek çok kişinin yapay zekadaki çalışmaların yüzde 80’ini temsil ettiğini iddia ettiği veri kalitesi üzerine bir kıyaslama veya rekabet için destek topluyor.
The Batch bülteninde, “Çoğu kıyaslama sabit bir veri seti sağlar ve araştırmacıları kod üzerinde yinelemeye davet eder… belki de kodu sabit tutmanın ve araştırmacıları verileri iyileştirmeye davet etmenin zamanı gelmiştir” diye yazdı.
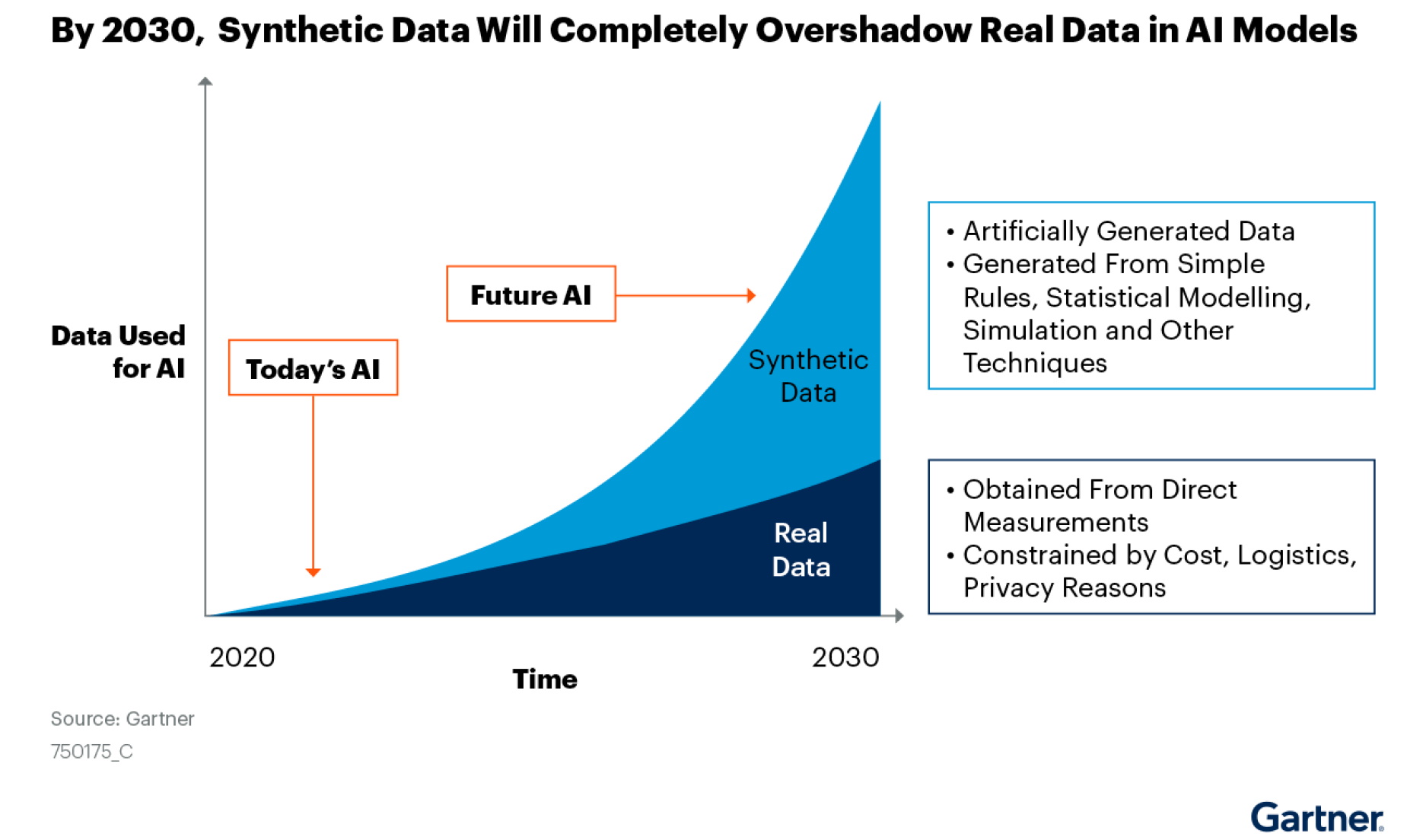
Sentetik verilerle ilgili Haziran 2021 raporunda Gartner, 2030 yılına kadar yapay zekada kullanılan verilerin çoğunun kurallar, istatistiksel modeller, simülasyonlar veya diğer teknikler tarafından yapay olarak oluşturulacağını tahmin ediyor.
Raporda, “Gerçek şu ki, sentetik veriler olmadan yüksek kaliteli, yüksek değerli yapay zeka modelleri oluşturamazsınız” dedi.
Artırılmış ve Anonimleştirilmiş Veri, Sentetik Verilere Karşı
Çoğu geliştirici, mevcut bir gerçek dünya veri kümesine yeni veriler eklemeyi içeren bir teknik olan veri artırmaya zaten aşinadır. Örneğin, yeni bir görüntü oluşturmak için mevcut görüntüyü döndürebilir veya parlaklaştırabilirler.
Gizlilikle ilgili endişeler ve hükümet politikaları göz önüne alındığında, kişisel bilgilerin bir veri kümesinden kaldırılması giderek yaygınlaşan bir uygulamadır. Buna veri anonimleştirme denir ve özellikle finans ve sağlık gibi sektörlerde kullanılan bir tür yapılandırılmış veri olan metin için oldukça popüler bir tekniktir.
Artırılmış ve anonimleştirilmiş veriler, tipik olarak sentetik veriler olarak kabul edilmezler. Ancak bu teknikleri kullanarak sentetik veriler oluşturmak mümkündür. Örneğin, geliştiriciler, iki araba ile yeni bir sentetik görüntü oluşturmak için gerçek dünyadaki arabaların iki görüntüsünü harmanlayabilir.
Sentetik Veriler Neden Bu Kadar Önemli?
Geliştiriciler, sinir ağlarını eğitmek için büyük ve dikkatle etiketlenmiş veri kümelerine ihtiyaç duyar. Daha çeşitli eğitim verileri genellikle daha doğru yapay zeka modellerine kapı açar.
Sorun şu ki, birkaç bin ila on milyonlarca öğe içerebilen veri kümelerinin toplanması ve etiketlenmesi, çoğu zaman aşırı derecede pahalı ve zaman alıcı bir iş oluyor. İlk özel sentetik veri hizmetlerinden biri olan AI.Reverie’nin kurucularından Paul Walborsky, bir etiketleme hizmetinden 6 dolara mal olabilecek tek bir görüntünün altı sent’e yapay olarak oluşturulabileceğini tahmin ediyor.
Maliyet tasarrufu sadece bir başlangıç. Walborsky, “Sentetik veriler, gerçek dünyayı temsil edecek veri çeşitliliğine sahip olmanızı sağlayarak gizlilik sorunlarıyla başa çıkmanın ve önyargıyı azaltmanın anahtarıdır” diyor.
Sentetik Verilerin Tarihçesi Nedir?
Sentetik veriler, onlarca yıldır şu veya bu biçimde var olmuştur. Uçuş simülatörleri gibi bilgisayar oyunlarında veya atomlardan galaksilere kadar her şeyin bilimsel simülasyonlarında süregelmiştir.
Harvard istatistik profesörü Donald B. Rubin, bir nüfus sayımında özellikle yoksul insanların eksik sayılması gibi sorunları çözmede ABD hükümetinin şubelerine yardım ediyordu. Bunu, genellikle sentetik verilerin doğuşu olarak anılan 1993 tarihli bir makalesinde açıkladı.
Rubin, “Bu makalede, çok sayıda simüle edilmiş veri kümesine atıfta bulunan sentetik veri terimini kullandım” dedi.
“Her biri, gerçek veri kümesini oluşturan aynı süreç tarafından yaratılmış gibi görünüyor, ancak veri kümelerinin hiçbiri herhangi bir gerçek veri göstermiyor. Bu, kişisel, gizli veri kümelerini incelerken çok büyük bir avantaj sağlıyor” diye ekledi.

Yapay Zekanın Büyük Patlama olan bir sinir ağının nesneleri bir insandan daha hızlı tanıdığı 2012 ImageNet yarışmasının ardından, araştırmacılar ciddi bir şekilde sentetik veriler için avlanmaya başladılar.
NVIDIA’da simülasyon teknolojisi ve yapay zeka kıdemli direktörü Gavriel State, birkaç yıl içinde, “araştırmacılar deneylerde işlenmiş görüntüleri kullanıyorlardı ve insanların 3D motorları ve içerik veri hatlarıyla veri üretmek için ürünlere ve araçlara yatırım yapmaya başlaması yeterince iyi sonuç verdi” dedi.
Ford, BMW Sentetik Veri Üretiyor
Bankalar, araba üreticileri, insansız hava araçları, fabrikalar, hastaneler, perakendeciler, robotlar ve bilim adamları bugün hala sentetik verileri kullanıyor.
Yakın tarihli bir podcast’te, Ford’dan araştırmacılar, yapay zeka eğitimi için sentetik veriler oluşturmak üzere oyun motorlarını ve çekişmeli üretken ağları (GAN’lar) nasıl birleştirdiklerini anlattılar.
BMW, otomobil yapma sürecini optimize etmek için, şirketlerin birden fazla araç kullanarak işbirliği yapmasını sağlayan NVIDIA Omniverse’i kullanarak sanal bir fabrika oluşturdu. BMW’nin ürettiği veriler, otomobilleri verimli bir şekilde üretmek için montaj işçileri ve robotların birlikte nasıl çalıştıklarına ince ayar yapılmasına yardımcı oluyor.
Hastane, Banka ve Mağazada Sentetik Veriler
Tıbbi görüntüleme gibi alanlardaki sağlık hizmeti sağlayıcıları, hasta mahremiyetini korurken yapay zeka modellerini eğitmek için sentetik verileri kullanır. Örneğin, bir girişim olan Curai, 400.000 simüle edilmiş tıbbi vaka üzerinde bir teşhis modeli eğitti.
Nikolenko, 2019 anketinde “Tıbbi görüntüleme için sentetik veriler üreten veya diğer alanlardan gerçek verileri uyarlayan GAN tabanlı mimariler, önümüzdeki yıllarda alandaki en son teknolojiyi tanımlayacak” dedi.
GAN’lar finans alanında da ilgi görüyor. American Express, yapay veri oluşturmak için GAN’ları kullanmanın yollarını araştırdı ve sahtekarlığı tespit eden AI modellerini geliştirdi.
Perakendede, Caper gibi şirketler, bir ürünün en az beş görüntüsünü almak ve bin görüntüden oluşan sentetik bir veri kümesi oluşturmak için 3B simülasyonları kullanıyor. Bu tür veri kümeleri, müşterilerin ihtiyaç duyduklarını aldıkları ve bir ödeme sırasında beklemeden gittikleri akıllı mağazalara olanak tanıyor.
Sentetik Veriler Nasıl Oluşturulur?
NVIDIA’dan State, sentetik veri üretmek için “Orada bir bazilyon teknik var” dedi. Örneğin, varyasyonel otomatik kodlayıcılar, bir veri kümesini kompakt hale getirmek için sıkıştırır, ardından ilgili sentetik veri kümesini oluşturmak için bir kod çözücü kullanır.
GAN’lar özellikle araştırmalarda yükselişteyken, simülasyonlar iki nedenden dolayı popüler bir seçenek olmaya devam ediyor. Durağan ve hareketli görüntüleri segmentlere ayırmak ve sınıflandırmak için bir dizi aracı destekleyerek mükemmel etiketler oluştururlar. Ayrıca farklı renk, ışık, malzeme ve pozlara sahip nesnelerin ve ortamların versiyonlarını hızlı bir şekilde üretebilirler.
Bu son durum yapay zeka modellerinin doğruluğunu artırmak için giderek daha fazla kullanılan bir teknik olan ‘alan rastgeleleştirme’ için önem arz eden sentetik verileri sunar.
Profesyonel İpucu: Alan Rastgeleleştirme Kullanın
Alan rastgeleleştirme, bir nesnenin ve ortamının binlerce varyasyonunu kullanır, böylece yapay zeka modeli genel kalıbı daha kolay anlayabilir. Aşağıdaki video, akıllı bir deponun yapay zeka destekli bir robotu eğitmek için alan rastgeleleştirmesini nasıl kullandığını gösterir.
Alanı rastgeleleştirme, bir AI modelinin belirli bir günde bulduğu tam durum üzerinde eğitilmiş olması durumunda yapacağı mükemmel tahminlerin eksikliğini kapatmaya yardımcı olur. Bu nedenle NVIDIA, GTC’de yakın zamanda yapılan bir konuşmada açıklanan çalışmanın bir parçası olan Omniverse’de sentetik veri oluşturma araçları için alan rastgeleleştirmeyi tasarlıyor.
Bu tür teknikler, bilgisayarla görü uygulamalarının görüntülerdeki nesneleri algılama ve sınıflandırmadan videolardaki etkinlikleri görme ve anlama aşamasına geçmesine yardımcı oluyor.
AI.Reverie’den Walborsky, “Piyasa bu yönde ilerliyor, ancak teknoloji daha karmaşık. Sentetik veriler, tamamen açıklamalı video kareleri oluşturmanıza izin verdiği için burada daha da değerlidir” dedi.
Sentetik Verileri Nereden Alınabilir?
Sektör sadece birkaç yaşında olmasına rağmen, 50’den fazla şirket sentetik veri sağlıyor. Her biri genellikle belirli bir düşey pazara veya tekniğe odaklanır.
NVIDIA, çok çeşitli sentetik veri ve veri etiketleme hizmetleriyle çalışmayı amaçlamaktadır. En son ortakları arasında:
- New York’ta bulunan AI.Reverie, kullanıcıların kendi veri kümelerini toplamasına olanak tanıyan yapılandırılabilir sensörlere sahip simülasyon ortamları sunuyor ve tarım, akıllı şehirler, güvenlik ve üretim gibi alanlarda büyük ölçekli projeler üzerinde çalışıyor.
- Londra merkezli Sky Engine, pazarlarda bilgisayarlı görü uygulamaları üzerinde çalışıyor ve kullanıcıların kendi veri bilimi iş akışlarını tasarlamalarına yardımcı oluyor.
- İsrail merkezli Datagen, otomobiller ve binalar için akıllı mağazalar, robotik ve iç mekanlar dahil olmak üzere çok çeşitli pazarlar için simülasyonlardan sentetik veri kümeleri oluşturuyor.
- CVEDIA, sentetik verilere dayalı bilgisayar görüsü için özelleştirilebilir araçlarının kullanıcıları arasında Airbus, Honeywell ve Siemens’i de içeriyor.
Omniverse ile Pazar Yeri Etkinleştirme
Omniverse ile NVIDIA, her sektörde sanal dünyalar oluşturmak veya bu dünyalarda işbirliği yapmakla ilgilenen tasarımcıların ve programcıların genişleyen bir ekosistemi etkinleştirmeyi amaçlıyor.
NVIDIA, Isaac Sim’i Omniverse’de robotik alanında bir uygulama olarak yarattı. Kullanıcılar, sentetik veriler ve alan rastgeleleştirme ile bu sanal dünyada robotları eğitebilir ve ortaya çıkan yazılımı gerçek dünyada çalışan robotlara dağıtabilir.
Omniverse, otonom araçlar için NVIDIA DRIVE Sim gibi düşey pazarlar için birden fazla uygulamayı destekliyor. Geliştiricilerin, otonom araçları gerçekçi bir simülasyonun güvenliğinde test etmelerine izin veriyor ve pandeminin ortasında bile faydalı veri kümeleri üretiyor.
Sentetik veriler hakkında daha fazla bilgi için şu kaynaklara göz atın:
- O’Reilly ve NVIDIA tarafından yapay zekada sentetik verilerin kullanılmasına ilişkin bir e-kitap
- NVIDIA simülasyon teknolojisi başkan yardımcısı Rev Lebaredian tarafından GTC 2019’da sentetik veriler üzerine bir konuşma (Ücretsiz kayıt gereklidir)
- 2021’de sentetik verilerle ilgili yayınlanan dört NVIDIA geliştirici blogu
- GTC 2021’de, Scotiabank ve Alberta Üniversitesi tarafından, sentetik veriler oluşturmak için üretken modelleri kullanan araştırmalar hakkında bir sunum (Ücretsiz kayıt gereklidir)
- Omniverse’de sentetik veri üretimi için kod içeren örnekler
Yazının kaynağına buradan ulaşabilirsiniz.
OPENZEKA HABERLERİ




OPENZEKA HABERLERİ
Hesaplarınızda paylaşmak ister misiniz?



